
نحوه انجام آزمون خی دو در spss
آزمونهای آماری استنباطی در تحلیل آماری به دو بخش عمده تقسیم میشوند: آزمونهای آمار استنباطی پارامتریک و آزمونهای آمار استنباطی ناپارامتریک. همانگونه که در تمامی کتابهای آماری ذکر شده و ما مجدد به تکرار آنها در اینجا نمیپردازیم، یکی از دلایل استفاده از آزمونهای پارامتریک وجود متغیری در پژوهش است که مقیاس آن رتبهای یا اسمی است. اگر چنین متغیری در پژوهش داریم میبایست برای انجام تحلیل آمار استنباطی از آزمونهای ناپارامتریک مانند آزمون خی دو استفاده کنید. با وب سایت چاپ مقاله اوج دانش همراه باشید.
+ بیشتر بخوانید: آشنایی با روش صحیح گزارش p-values در مقالات
+ از طریق گروه مترجمان نیتیو پیپر (Native paper) مقاله خود را دقیق ترجمه کنید
در اینجا قصد داریم به آموزش نحوه انجام آزمون خی دو در spss بپردازیم و مانند آموزشهای دیگر کار با با یک مثال شروع میکنیم. فرض کنید دو گروه آزمایش و کنترل داریم که میخواهیم تحصیلات و جنسیت این دو گروه را با یکدیگر مقایسه نماییم. هر دو متغیر ذکر شده در این پژوهش مقیاس اسمی دارند و میبایست برای انجام چنین مقایسهای از آزمون خی دو استفاده نماییم.
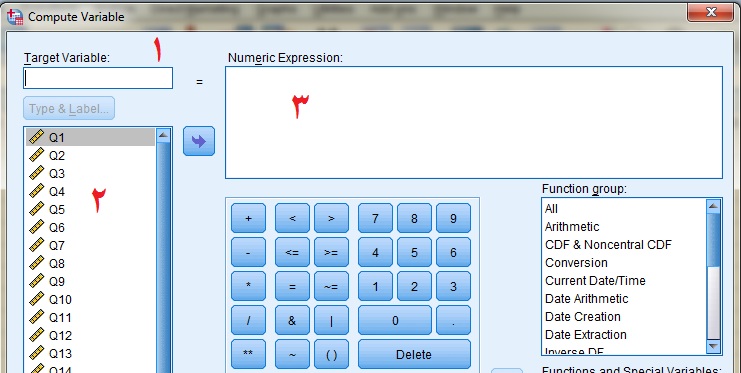
مرحله اول: بعد از ورود دادهها به spss به منوی بالایی آن رفته و دستور زیر را اجرا میکنید:
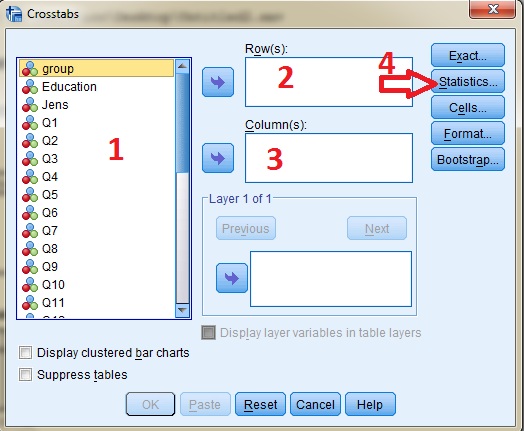
![]() با اجرای دستور فوق پنجره زیر باز میشود. همانگونه که با عدد و فلش مشخص شده است، در این پنجره با ۴ قسمت عمده کار خواهیم کرد. همانگونه که میبییند در کادر ۱ سه متغیر جنس، تحصیلات و گروه بعلاوه سوالات پرسشنامه وارد شده است.
با اجرای دستور فوق پنجره زیر باز میشود. همانگونه که با عدد و فلش مشخص شده است، در این پنجره با ۴ قسمت عمده کار خواهیم کرد. همانگونه که میبییند در کادر ۱ سه متغیر جنس، تحصیلات و گروه بعلاوه سوالات پرسشنامه وارد شده است.
 نحوه انجام آزمون خی دو در spss
نحوه انجام آزمون خی دو در spss
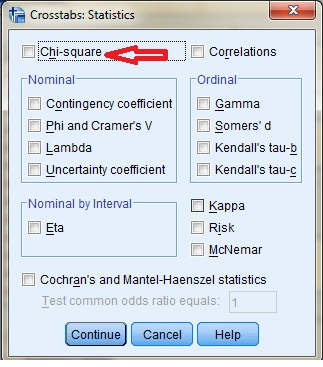
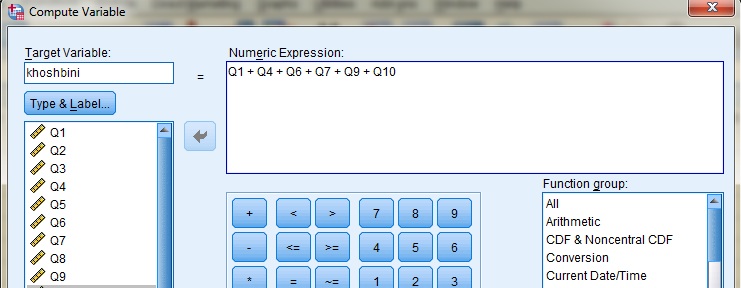
مرحله دوم: در گام اول میخواهیم متغیر تحصیلات را در میان دو گروه آزمایش و کنترل بررسی کنیم. هدف از این بررسی مقایسه فراوانی افراد گروه آزمایش و کنترل برحسب طبقات تحصیلات (لیسانس، فوق لیسانس و دکترا) است. در این کادر تحصیلات را که در اینجا با نام (Education) آمده به کادر Row و گروه (group) را به کادر Column انتقال میدهیم. توجه داشته باشید که اگر جای این دو متغیر را برعکس نیز انتقال دهید اتفاق خاصی نمیافتد و در نتایج تغییری رخ نخواهد داد. یعنی اگر گروه در سطر (Row) و تحصیلات در ستون (Column) باشد. بعد از انتقال متغیرهای خود به کادر ۲ و ۳ قبل از کلیک بر روی دکمه ok بر روی قسمت ۴ که دکمهای با نام statistics است کلیک میکنیم. با کلیک بر روی این گزینه پنجرهای به شکل زیر باز میشود:
 نحوه انجام آزمون خی دو در spss
نحوه انجام آزمون خی دو در spss
مرحله سوم: بر روی شکل مربع بغل کلمه chi-square کلیک کنید تا انتخاب شود. بعد از انتخاب بر روی continue کلیک کنید تا به پنجره باز شده در مرحله اول بازگردید. آنگاه دکمه ok کلید کنید تا محاسبه انجام شود و خروجیها ارایه گردند. در زیر خروجی مربوط به این محاسبه آورده شده است.
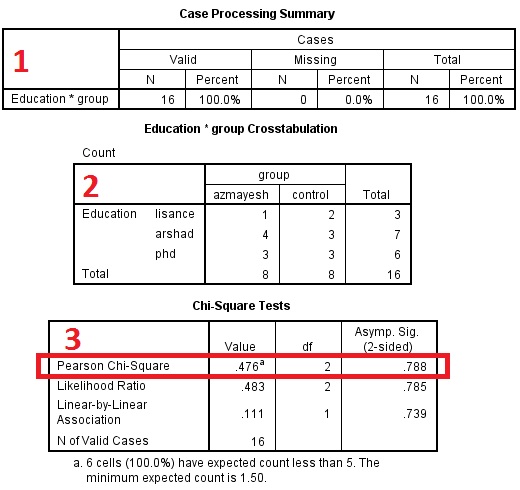 برای گزارش نتایج خروجیها جدول شماره ۱ را کنار بگذارید. جدول دو فراوانی هریک از گروهها را در سه طبقه متغیر تحصیلات نشان داده است که با اهمیت است و جدول ۳ نتیجه آزمون خی دو را برای مقایسه فراوانی دو گروه در سه طبقه تحصیلات نشان میدهد. سطر اول این جدول که با کادر قرمز رنگ نیز مشخص نمودهایم به ترتیب میزان خی دو (۰/۴۷)، درجه آزادی (۲)، و ارزش p را نشان میدهد (۰/۷۸). میتوانید برای این خروجی جدولی به مختصات زیر ترسیم نمایید (p-Value در تحلیل آماری چه اطلاعاتی به شما می دهد؟).
برای گزارش نتایج خروجیها جدول شماره ۱ را کنار بگذارید. جدول دو فراوانی هریک از گروهها را در سه طبقه متغیر تحصیلات نشان داده است که با اهمیت است و جدول ۳ نتیجه آزمون خی دو را برای مقایسه فراوانی دو گروه در سه طبقه تحصیلات نشان میدهد. سطر اول این جدول که با کادر قرمز رنگ نیز مشخص نمودهایم به ترتیب میزان خی دو (۰/۴۷)، درجه آزادی (۲)، و ارزش p را نشان میدهد (۰/۷۸). میتوانید برای این خروجی جدولی به مختصات زیر ترسیم نمایید (p-Value در تحلیل آماری چه اطلاعاتی به شما می دهد؟).
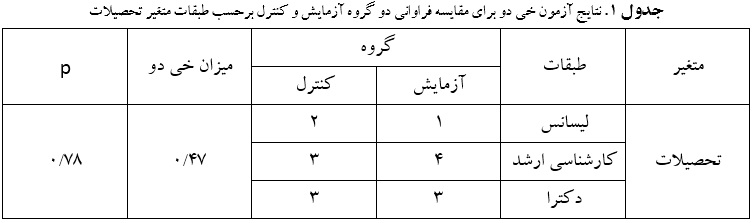 در تفسیر جدول فوق هم چنین می نویسیم که میزان خیدو بدست آمده حاصل از مقایسه فراوانیهای دو گروه در سه طبقه متغیر تحصیلات برابر با ۰/۴۷ میباشد که این میزان به لحاظ اماری معنادار نمیباشد (۰/۷۸=p). بنابراین دو گروه مورد مطالعه از نظر تحصیلات تفاوت معناداری بایکدیگر ندارند.
در تفسیر جدول فوق هم چنین می نویسیم که میزان خیدو بدست آمده حاصل از مقایسه فراوانیهای دو گروه در سه طبقه متغیر تحصیلات برابر با ۰/۴۷ میباشد که این میزان به لحاظ اماری معنادار نمیباشد (۰/۷۸=p). بنابراین دو گروه مورد مطالعه از نظر تحصیلات تفاوت معناداری بایکدیگر ندارند.
دقیقا همین مراحل را برای متغیر جنس تکرار نمایید تا نتایج آزمون خی دو برای این متغیر نیز بدست آید. مرکز تحقیقاتی اوج دانش افتخار دارد با ارایه خدماتی همچون ترجمه نیتیو مقالات و چاپ مقالات در خدمت پژوهشگران عزیز است. برای اطلاع از جزییات خدمات با ما در تماس باشید.
لینکهای مفید دیگر
پروتکلهای مداخله روانشناسی بر اساس رویکردهای درمانی مختلف





 از بین جداول فوق مهمترین جداول برای ارائه نتایج نهایی جدول خلاصه مدل (Model Summary) و جدول ضرایب میباشد (Coefficients). ما برای ارائه نتایج نهایی ترسیم جدول زیر را پیشنهاد میکنیم (توجه داشته باشید که اطلاعات مندرج در جدول ۱ تماماً ساختگی است و دادهها واقعی نیستند):
از بین جداول فوق مهمترین جداول برای ارائه نتایج نهایی جدول خلاصه مدل (Model Summary) و جدول ضرایب میباشد (Coefficients). ما برای ارائه نتایج نهایی ترسیم جدول زیر را پیشنهاد میکنیم (توجه داشته باشید که اطلاعات مندرج در جدول ۱ تماماً ساختگی است و دادهها واقعی نیستند):